Tensei-Data – Bridging the data gap!
A quantum leap forward in areas of data integration and interface management. Increase the efficiency of your IT processes with Tensei-Data.
Imagine, you integrate, migrate & transform data with ease!
Your benefits
Up to
80%
less effort
About
50%
less cost
Nearly
100%
reusability
Lower your financial and human costs, standardize and structure your existing IT processes and discover entirely new use cases.
Why?
Tensei-Data can be used to merge, standardize and simplify data integration, data migration, data transformation and interface management processes which increases efficiency and reduces costs.
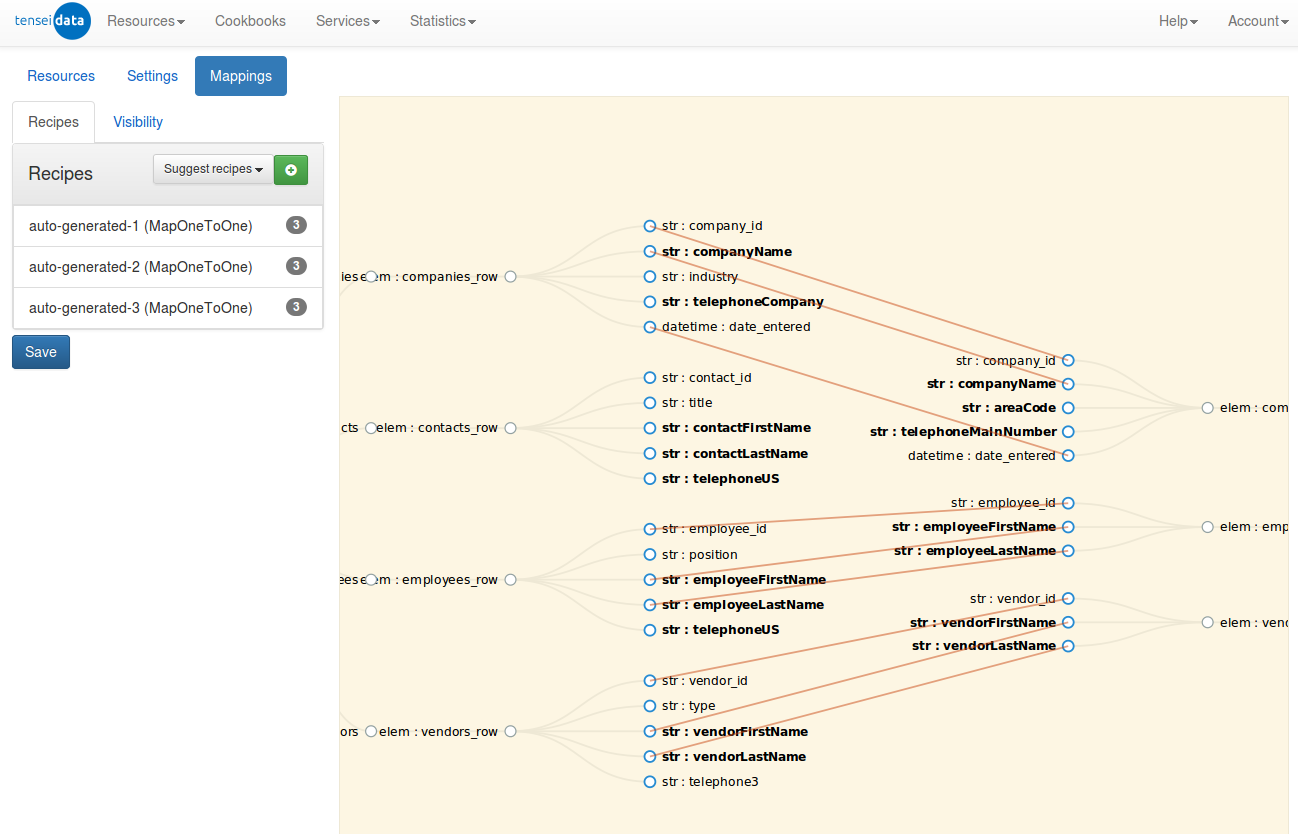
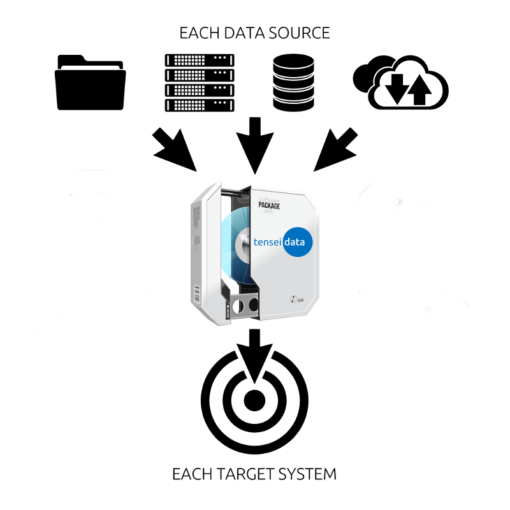
This solution is based on the modern technology stack of Akka and Scala. That leads to a high performant, scalable and very flexible application. We can connect and automatically describe almost any source and target system with our dynamic connectors. In the next step you can map the data sources in an intuitive way. In this step, data can be transformed as often as needed to meet the requirements of the target system.
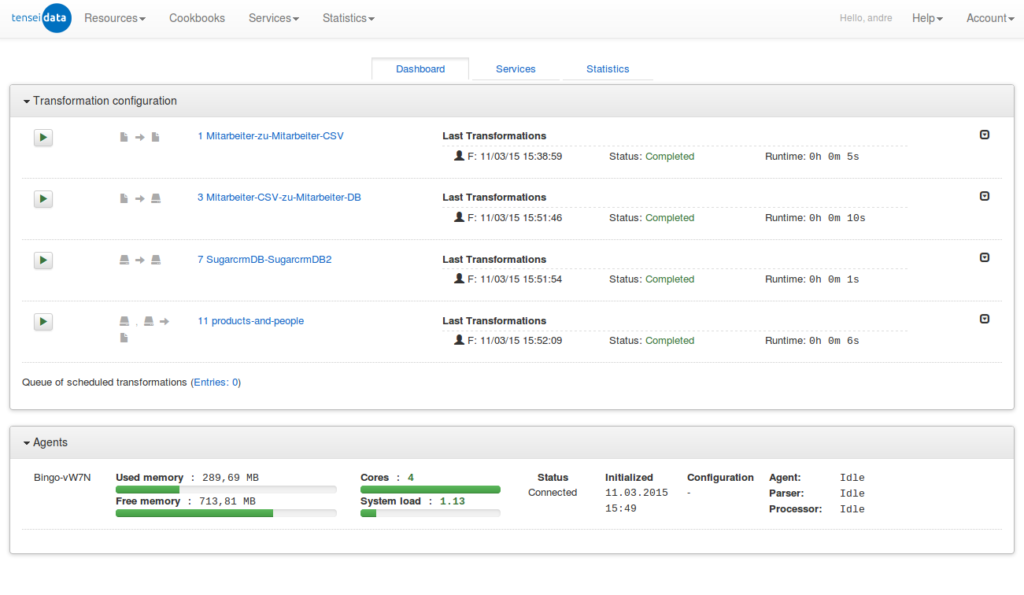
Transformers for the basic issues are already included. Moreover it is possible to automatically execute data integration task by the help of Cronjobs and Triggers. Of course, all work flows can be reused. This avoids additional costs for same or similar processes.
Key features of Tensei-Data
In the future, data management must become simpler and cover as many applications as possible. Diverse features are provided to solve minor issues right up to complex tasks.
- Dynamic Connectors
- Referential Integrity
- Normalization
- Virtual Views
- Transformers
- Automatic execution
- Scalable
- Diverse database systems and file types
Overview of database and file connectors
Tensei-Data supports various databases and provides connection out of the box.
| Databases | Files | File Access |
|---|---|---|
| Derby | Text | Local |
| H2 | CSV | Http |
| HyperSQL | XML | FTP |
| Firebird | Excel | FTPS |
| MariaDB | JSON | SFTP |
| Microsoft SQL Server | ||
| MySQL | TSV | |
| Oracle | ||
| PostgreSQL | ||
| SQLite | ||
| others (via JDBC) |
Additional features
- Automatic description of the data structure
- Complex integration tasks can be subdivided into subtasks and automatically executed
- Besides the graphical frontend exists an admin mode that allows the specification of database dependent queries
- Filtering of data
- Export / Import of existing cookbooks for reuse
- Intuitive mapping visualization
- Extreme short training periods
Search Technology / Enterprise Search
Enterprise Search and Search Technologies for individual use cases.
- Real-time Search
- Individual sorting
- Pre-selection and post-filtering
- Modular infrastructure
- Search profiles
- Facets / Filters
- Look-Ahead-Mode
- Hybrid-Search
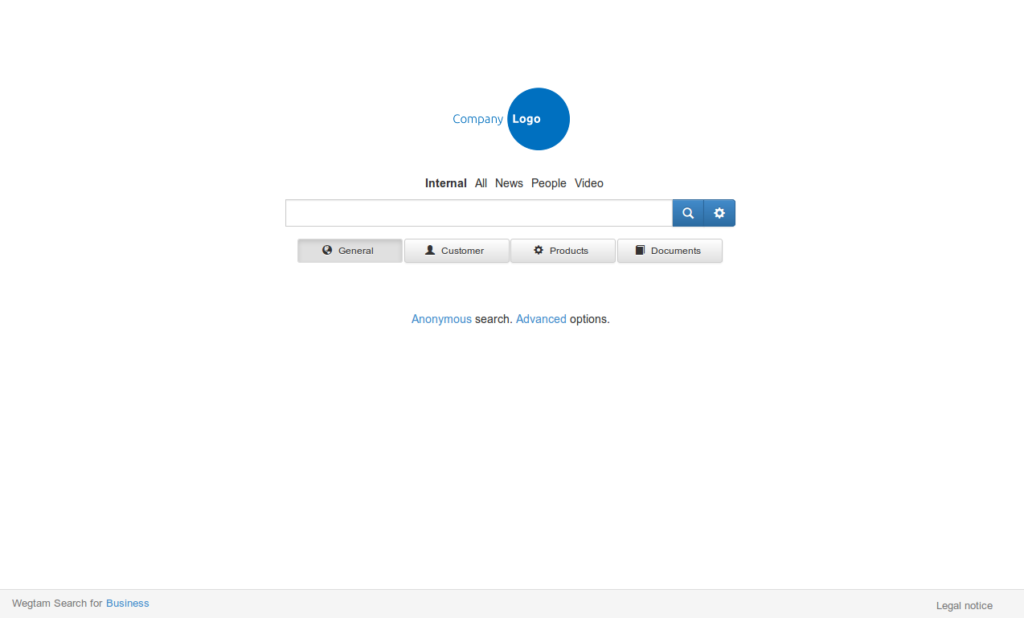
Data information and knowledge is our passion
Finding information is a time-intensive process that consumes between 5-20% of the working time depending on the sector. In addition, the amount of data will increase continuously in the coming years and the effort for the search will rise. If one scales such search processes on several employee and year, quickly emerge high costs in five- to six-figure range.
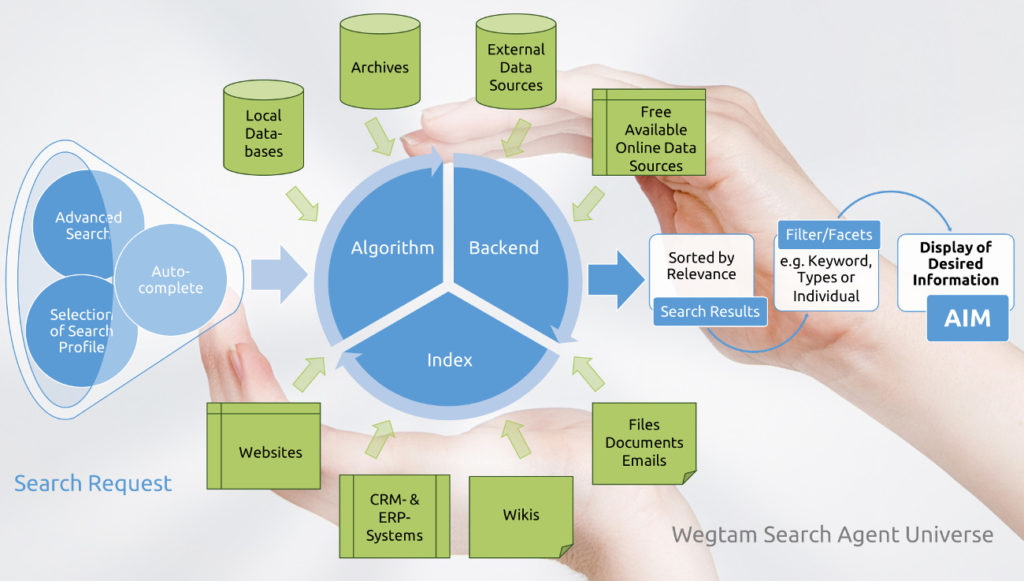
We offer a search technology solution for public institutions and SMEs, as well as an enterprise search solution for large enterprises. Thus, we provide a comprehensive search over distributed data sources such as files, documents, emails, local databases, wikis, internal and external databases, websites, CRM, ECM, ERP’s, archive solutions, as well as all previously affiliated online data sources.
The search solution provides real-time search on previously indexed data (based on Lucene , the number 1 of the full-text search engines) coupled with a search on the entire data stock. The displayed search results can be refined via facets / filters in real time. Thereby, the relevant content is found even faster.
The flexibility , robustness and security of the system in conjunction with a low effort for maintenance and minimal impact on corporate resources are additional technological features. Moreover, large data sets in structured and unstructured form can be searched with this system.
Key features of the Wegtam Search Agent
The Wegtam search technology integrates and connects various external and internal data sources for a comprehensive search. Regardless of the number of the data sources (one data base ↔ diverse data bases, indexed data ↔ not-indexed data), the Wegtam Search technology enables a configurable and adaptable search environment.
Simply use the Wegtam Search Technology, if you want to search over databases, documents (Word, PDF, etc.), web-content, content management systems, wiki’s (e.g. MediaWiki) or enterprise products (e.g. Trac, SugarCRM).
- Realtime search
- Sorting by relevance and content
- Pre-selection and post-filtering
- Native integration or via REST API
- Modular infrastructure
- Search profiles
- Facets / Filters
- Advanced search
- Security / SSL
- LAM – Look-Ahead-Mode
- VM – Virtual Machine